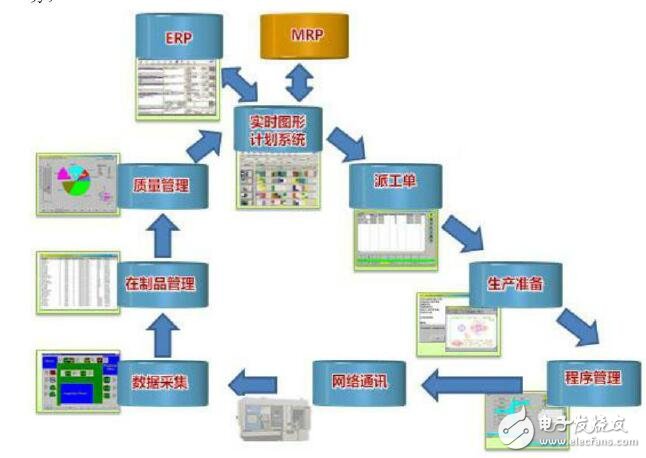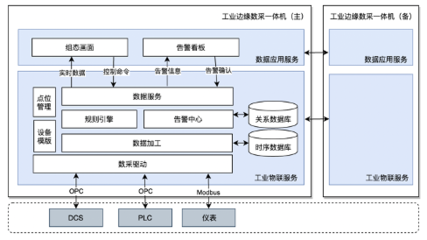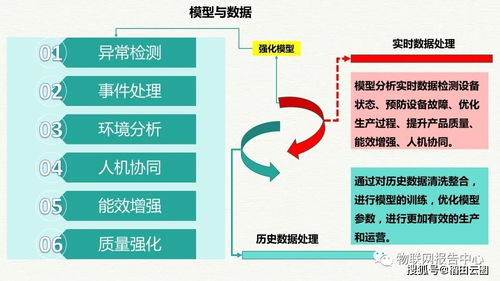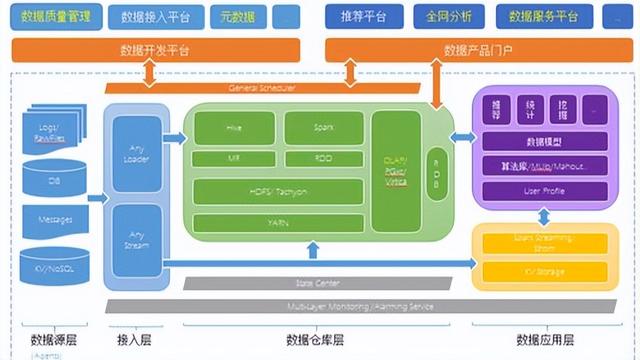
在数字化时代,数据已成为企业最宝贵的资产之一。构建一个高效、可扩展且稳健的数据处理系统,离不开精心设计的大数据架构图。这不仅是一个技术蓝图,更是连接数据源头与业务价值的关键桥梁。本文旨在探讨大数据架构图设计的核心要素,以及如何构建一个高效的数据处理服务。
一、 大数据架构图的核心构成
一个典型的大数据架构图通常遵循分层设计理念,以实现逻辑清晰、职责分离和灵活扩展。其核心层次通常包括:
- 数据采集与接入层: 这是数据管道的起点。负责从各种异构数据源(如业务数据库、应用程序日志、物联网设备、第三方API等)实时或批量地采集数据。常见的工具有Apache Kafka(用于实时流)、Apache Flume、Sqoop以及云服务商提供的各种数据迁移工具。
- 数据存储层: 根据数据的热度、访问模式和结构,选择合适的存储方案。这通常是一个混合存储体系:
- 批处理数据湖: 使用如Hadoop HDFS或云对象存储(如AWS S3,阿里云OSS)来低成本、高可靠地存储原始数据,支持任意格式,为后续探索性分析奠定基础。
- 实时/交互式数据库: 如Apache HBase、Cassandra,用于低延迟的随机读写。
- 分析型数据仓库: 如Apache Hive on Tez/Spark、云数据仓库(如Snowflake,阿里云MaxCompute),用于对清洗后的数据进行复杂的SQL查询和分析。
- 数据处理与计算层: 这是架构的“引擎”,负责将原始数据转化为有价值的信息。它通常分为两条并行的处理路径:
- 批处理路径: 处理海量历史数据,计算周期长(如小时、天)。核心引擎是Apache Spark(因其内存计算和易用性已成为主流)或MapReduce。
- 流处理路径: 处理无界数据流,实现亚秒级到秒级的低延迟分析。常用框架有Apache Flink(因其高吞吐、低延迟和精确一次语义而领先)、Apache Spark Streaming以及Kafka Streams。
- 数据服务与应用层: 将处理好的数据以服务的形式暴露给下游应用。这包括:
- OLAP分析服务: 通过Presto、Druid、ClickHouse等提供高速多维分析。
- 数据API服务: 通过RESTful API或GraphQL将数据提供给业务系统、数据产品(如推荐系统、风控模型)和可视化报表。
- 数据治理与安全层(贯穿始终): 这不是一个独立的物理层,而是横跨所有层次的关键能力。它包括元数据管理(如Apache Atlas)、数据血缘追踪、数据质量管理、统一的安全认证与权限控制(如Apache Ranger),确保数据的可靠性、可信度与合规性。
二、 构建高效数据处理服务的关键原则
在设计架构图时,应遵循以下原则以确保数据处理服务的高效性:
- Lambda与Kappa架构的抉择与融合: 经典的Lambda架构同时维护批处理和流处理两套逻辑,保证容错但存在代码重复。Kappa架构主张用一套流处理系统处理所有数据,简化了架构。在实践中,可根据业务场景融合两者,例如用流处理处理实时需求,同时定期用批处理进行数据重算和纠偏。
- 解耦与弹性扩展: 各层次之间通过消息队列(如Kafka)或对象存储解耦,允许各组件独立扩展,提高系统整体的弹性和容错能力。利用云原生的弹性伸缩能力可进一步优化成本与性能。
- “可观察性”设计: 从架构设计之初就集成全面的监控(Metrics)、日志(Logging)和追踪(Tracing),实时掌握数据管道的健康状态、处理延迟和数据质量,便于快速定位和解决问题。
- 自动化与DevOps: 将数据管道即代码(Pipeline as Code),利用CI/CD工具实现数据处理作业的自动化测试、部署和运维,提升开发运维效率与系统可靠性。
三、 架构图设计实践:一个简化的示例流程
以一个电商用户行为分析场景为例,其简化的大数据架构流程可描述为:
- 用户在前端的点击、浏览、购买等日志,通过SDK实时发送到Apache Kafka(数据接入层)。
- 一个Apache Flink实时作业(流处理层)消费Kafka中的数据,进行实时过滤、聚合(如实时热门商品),并将结果写入Apache Druid(数据服务层)用于实时大盘展示,同时将原始数据备份到云对象存储S3(数据湖存储层)。
- 每日凌晨,一个Apache Spark批处理作业(批处理层)从S3中读取全天数据,进行更复杂的清洗、关联(如连接用户属性表)和聚合,生成结构化的业务宽表,并写入云数据仓库(如Snowflake,分析存储层)。
- 业务分析师通过BI工具(如Tableau,应用层)连接数据仓库和Druid,进行自助分析与报表制作。推荐系统通过数据API(数据服务层)调用处理后的用户画像和商品特征数据。
- 统一元数据与权限管理系统(治理层)监控整个流程的数据血缘,并管理各层数据的访问权限。
###
一张优秀的大数据架构图,是技术选型、流程设计与业务目标紧密结合的产物。它没有一成不变的标准答案,但核心在于平衡实时性与准确性、灵活性与成本、开发效率与系统稳定性。随着云原生、湖仓一体(Lakehouse)和流批一体(如Flink)等技术的发展,现代大数据架构正朝着更简化、更统一、更智能的方向演进。设计者需要持续关注技术趋势,并始终以解决实际业务问题、高效释放数据价值为最终目标来绘制和迭代这张至关重要的技术蓝图。