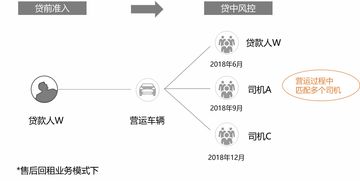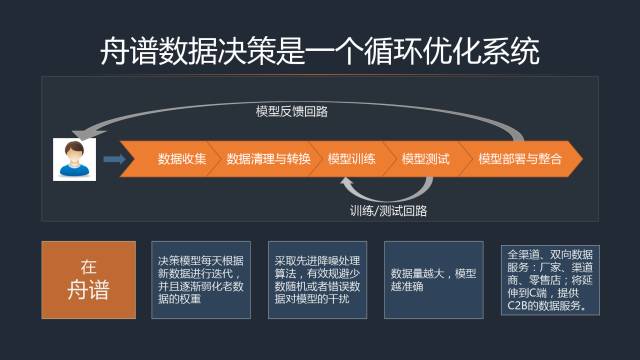
在网络安全领域,态势感知已成为主动防御的核心手段,它通过收集、分析和理解环境中的安全数据,以预测和应对潜在威胁。随着威胁的日益复杂化和数据量的爆炸式增长,传统的基于规则或签名的检测方法已显乏力。机器学习(Machine Learning, ML)因其强大的模式识别和预测能力,正被深度整合到安全态势感知系统中,以实现更智能、自适应的威胁检测与响应。机器学习模型的性能高度依赖于输入数据的质量。因此,数据预处理与特征工程作为数据处理服务中的关键环节,直接决定了安全态势感知系统的准确性与可靠性。
一、安全数据的特点与挑战
安全数据通常具有高维度、不平衡、噪声多和动态变化等特点。例如,网络流量日志、系统事件、用户行为记录等数据源不仅规模庞大,而且正常事件远多于攻击事件,导致数据类别极不平衡。攻击者常采用混淆、加密或低频攻击等手段,使得恶意模式隐藏在大量正常行为中,增大了检测难度。原始数据中的缺失值、异常值和不一致格式也会对模型训练产生负面影响。因此,未经处理的数据往往无法直接用于机器学习模型,必须通过专业的数据处理服务进行优化。
二、数据预处理:构建高质量数据基础
数据预处理是清洗和转换原始数据的过程,旨在提升数据的可用性。在安全态势感知中,这包括多个步骤:
1. 数据清洗:处理缺失值(如使用均值填充或删除记录)、纠正错误数据(如统一时间戳格式)、去除重复条目。例如,在分析网络入侵检测数据时,需清理因设备故障产生的异常日志。
2. 数据集成:将来自防火墙、IDS、终端设备等多源数据融合,消除冗余并解决不一致问题,以形成统一的安全视图。这通常需要借助数据管道和ETL(提取、转换、加载)工具实现。
3. 数据变换:对数据进行规范化或标准化,使不同尺度的特征(如数据包大小与请求频率)具有可比性。对于非线性数据,可能还需应用对数或指数变换。
4. 处理不平衡数据:针对安全数据中攻击样本稀少的问题,采用过采样(如SMOTE算法)或欠采样技术,以避免模型偏向多数类。
通过预处理,安全数据变得更加“干净”和结构化,为后续特征工程奠定基础。
三、特征工程:提取安全威胁的“指纹”
特征工程是从预处理后数据中提取、选择或构造特征的过程,这些特征应能有效表征安全事件的性质。在安全领域,特征工程常被视为一种艺术与科学的结合,因为它需要领域知识(如对攻击手法的理解)与数据分析技能。主要包括:
1. 特征提取:从原始数据中推导出有意义的指标。例如,从网络流量中提取“每秒连接数”、“协议类型分布”、“数据包负载熵值”等;从用户行为日志中提取“登录失败频率”、“文件访问模式”等。这些特征能捕捉正常与异常行为的差异。
2. 特征构造:通过组合或变换现有特征创建新特征,以增强模型表达能力。例如,将“源IP地址”与“目标端口”结合为交互特征,或基于时间序列数据计算滚动统计量(如过去一小时内同一IP的请求次数)。
3. 特征选择:从大量特征中筛选出最相关、非冗余的子集,以减少计算复杂度并防止过拟合。方法包括过滤法(如基于相关系数)、包裹法(如递归特征消除)和嵌入法(如Lasso回归)。在安全场景中,特征选择有助于聚焦于关键威胁指标,提升检测效率。
有效的特征工程能显著提高机器学习模型(如随机森林、深度学习网络)的精度,使其更准确地识别DDoS攻击、恶意软件传播或内部威胁等。
四、数据处理服务的实践与趋势
在实际部署中,安全态势感知系统往往依赖专业的数据处理服务来管理整个数据流水线。这些服务提供自动化工具和平台,支持实时或批处理模式,确保数据从采集到模型输入的顺畅流动。例如,利用Apache Spark进行大规模数据预处理,或使用特征存储(Feature Store)系统来维护和复用特征。随着边缘计算和物联网的发展,数据处理服务正向分布式和低延迟方向演进,以应对边缘安全设备的实时分析需求。隐私增强技术(如差分隐私)也被整合到预处理中,在保护敏感信息的同时不牺牲分析效果。
数据预处理与特征工程是连接原始安全数据与智能机器学习模型的桥梁。它们通过去除噪声、平衡分布、提取关键特征,将杂乱无章的数据转化为可操作的洞察,赋能安全态势感知系统实现从被动响应到主动预测的跨越。随着自动化机器学习(AutoML)和领域自适应技术的发展,数据处理服务将更加智能化,进一步降低安全运营的负担,提升网络空间的整体韧性。